


November 16, 2023
By Ryan Douglas and Anil Tolwani, Ace Data Scientists
To create world-class models, we need world-class data.
Quality data is at the heart of any high-performing AI model, but wrangling data into a
”modeling ready” state can be challenging and time-consuming. This is especially the case with clinical data, which is often noisy, lacks standardization, or requires clinical expertise just to be able to judge its quality.
At Unlearn, we’ve built a data processing toolkit to meet this challenge. Our approach values balancing flexibility with standardization. It enables us to build and deploy ETL (Extract, Load, Transform) pipelines capable of handling the complexities of clinical data while still ensuring high data quality.
Standardizing our Data API
Generally speaking, what it means for a dataset to be “modeling ready” is different for different modeling architectures. At Unlearn, we have developed a novel modeling architecture that is capable of handling common data quality issues, such as missing data, that many other architectures struggle with. We’ve been able to build this more robust architecture thanks in part to the high quality and standardization of our datasets.
The term API (Application Programming Interface) is used to describe a set of rules between two applications that define how they communicate. In the same sense, we define our own data API that dictates a standard way for our modeling architecture to interact with our datasets. At a high level, this means standardizing how we process, format, package, and release our datasets so that our machine learning engineers and data scientists can make reliable assumptions about the data before they even see it.
The key here is standardization in both the structure of the processed dataset and how the data processing is carried out. We need ETL pipelines that are capable of ingesting clinical data from a variety of different sources, harmonizing them into a cohesive dataset, and conforming that dataset to the rules of our data API.
So, how is this accomplished?
Harmonizing Clinical Data: The 80% Case
A common paradigm with ETL pipelines is to set them up to consume data with a consistent format on a fixed schedule. Because of the consistency of the data, these pipelines can afford to be rigid. Unfortunately, clinical data—as anyone who has worked with it knows—is anything but consistent. In fact, the sheer variety in structure, format, and quality of the data sources we need to harmonize necessitates a highly flexible data processing approach. Not only that, but the people processing the data need to effectively be domain experts in order to understand and accurately process data for a given disease area.
What makes this especially challenging is that we must balance the need for flexibility against the standardization required to meet our data API and ensure high data quality. To address this challenge, we’ve built a data processing toolkit geared towards processing what we refer to as the “80% case”. That is, our data processing toolkit must be able to handle at least 80% of the data we receive out of the box.
The 80% case represents a variety of transformations, data quality issues, and formatting operations we’ve deemed necessary to address across the vast majority of clinical data sources we’ve encountered. Some examples of common 80% operations are removing physically impossible values, standardizing lab units from different sources, handling duplicate data, pivoting tables, aggregating questionnaire scores, the list goes on.
Focusing on these defined cases allows us to establish a framework to build our data processing toolkit around. This toolkit is capable of building and deploying ETL pipelines composed of a standard set of configurable processing steps that address the 80% case. These processing steps are highly modular, allowing us to monitor the intermediate outputs of each step and trace exactly how we got from disparate clinical data sources to a cohesive, standardized dataset. This means that each pipeline run effectively generates a data processing audit trail.
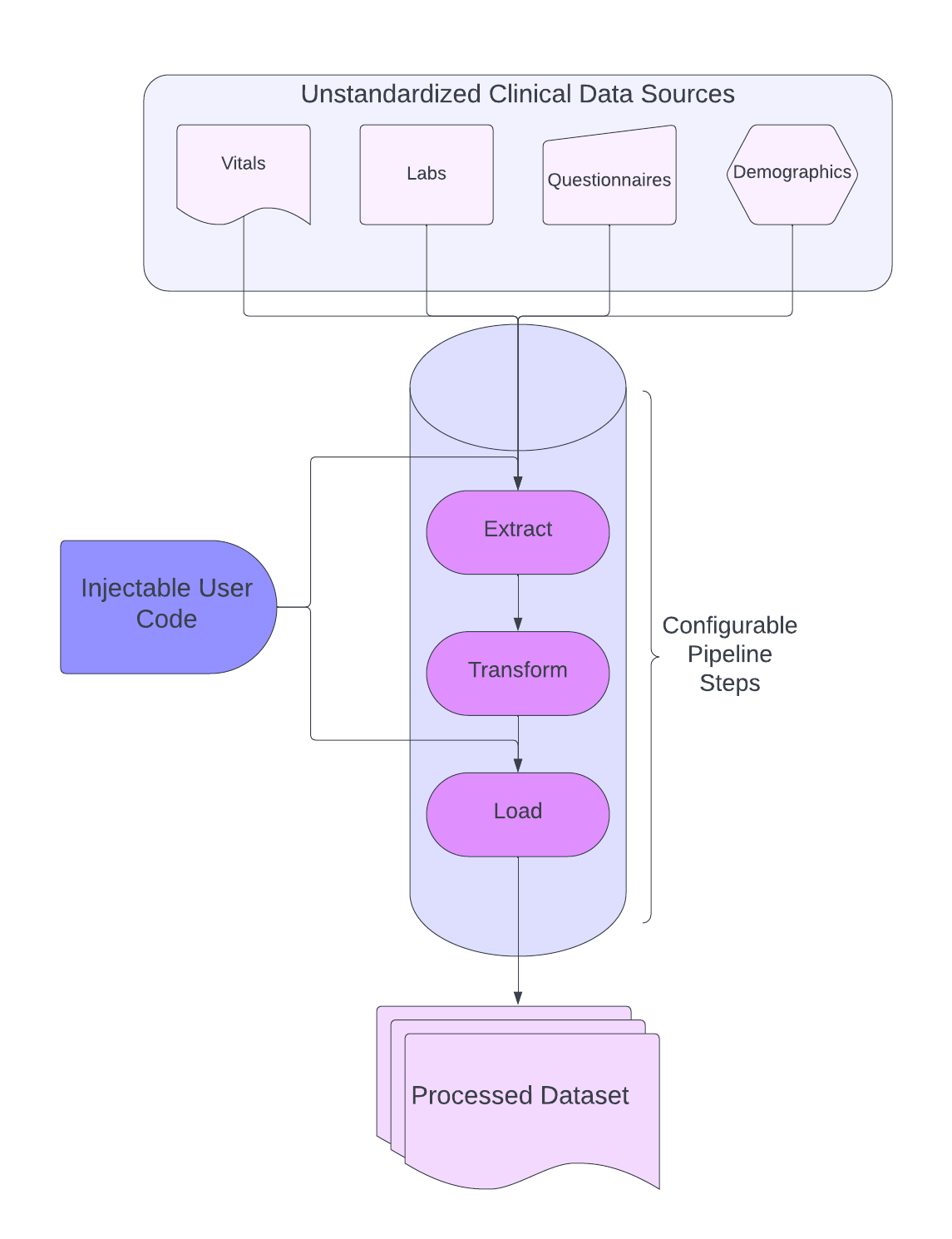
Enabling Clinical Data Scientists to Become Data Engineers
Now that we’ve covered the 80%, you’re probably wondering about the remaining 20%. These are unique cases that are difficult to anticipate and often require specialized handling. At Unlearn, we have a team of clinical data scientists who are experts at dealing with just such cases. They are responsible for gathering domain knowledge for a given disease indication, deciding what data needs to be in the final processed dataset, and how that data should be processed. When our clinical data scientists come across a situation that falls under the 20% case, we allow them to inject their own code into the pipeline. This allows them to perform any specialized operations needed to convert the 20% case into the 80% case.
Because they are injecting their own code directly into the pipeline, the code they write is still subject to the same data quality checks, standardization, and traceability as the rest of the pipeline. This allows our clinical data scientists to focus on the needs of the data rather than the engineering housekeeping that comes with deploying ETL pipelines. It’s this combination of injectable user code and configurable standardized steps that enables us to build pipelines flexible enough to address the challenges of clinical data while adhering to our data API.
What’s next?
To date, our data processing toolkit has been used to harmonize clinical data from over 170,000 patients across nine different indications. However, flexibility often comes at the expense of speed, and our ETL pipelines can be time-consuming to configure. With a backlog of over 500,000 patient records from 33 indications that still need harmonizing, this is a challenge we are confronting head-on. In part 2, we’ll share how we are employing automation to tackle this problem.
To learn more about how we use data, stream our recent Endpoints webinar led by Unlearn’s VP of Tech, Alex Lang, called “Data: The unsung hero of AI.”






