


June 26, 2023
We are very excited to unveil a new generation of Unlearn’s Digital Twin Generator (DTG) model architecture. This new architecture offers comprehensive, stochastic time-series forecasts of disease progression with significantly higher accuracy compared to the previous generation. Moreover, it incorporates greater sensitivity to individual characteristics of trial participants, further enhancing its predictive capabilities. This breakthrough immediately increases the value of our existing TwinRCT solutions and unlocks novel capabilities that provide even more benefits to our customers. Long clinical trial timelines everywhere should be very scared.
Recall that a DTG is a machine learning (ML) model that generates probabilistic forecasts of disease progression from a trial participant’s baseline measurements and other contextual information. Essentially, the model can extend a participant's clinical records into the future as if running the clock forward. To do so, it must capture the complex interactions between all of the variables in play. It must not only make predictions but accurately model the distributions of likely outcomes. It must function in the presence of missing data and handle data of all modes (categorical, ordinal, continuous, etc.)—and do this well—even with only a single measurement for the trial participant. This is an incredibly hard machine-learning problem. Fortunately, our new approach is suited to the challenge.
The new architecture employs an autoregressive time series model combining several modular components to provide a comprehensive, flexible, and extensible approach to digital twin generation. The design adheres to the principle of "simple modularity." While the components may be individually simple, the architecture as a whole is complex enough to handle the extensive set of requirements that DTG must satisfy. The simplicity of its parts facilitates troubleshooting, model interpretation, and targeted improvements, empowering our ML researchers and engineers to harness the technology effectively.
The backbone of the model architecture is a feedforward neural network known as the "point predictor," denoted here as p(v_0, c, t). This component predicts the expected values of longitudinal variables (v_t) at future time points (t) based on baseline values (v_0) and static context variables (c). The point predictor offers deterministic, participant-specific predictions of expected values. Each participant's likely outcome trajectories exhibit variations around this predicted progression.
But the trajectories don’t exhibit purely random variations. Instead, they vary according to learned multivariate distributions. To capture the intricate multivariate distribution of the variables, we employ a parametrized family of Restricted Boltzmann Machines (RBMs) known as a "neural RBM [Neural Boltzmann Machines]." In this setting, the RBM is parametrized to learn a mean (\mu), precision (P), and weights (W) between visible and hidden RBM units. Using feedforward neural networks to condition the RBM mean and precision parameters on a participant's baseline and context features makes it possible to regard the RBM as a family of structured noise distributions centered around the predicted mean with predicted precision. This family of RBMs can be sampled to ultimately provide the full probabilistic distribution of trial participant trajectories.
Real clinical trajectories exhibit autocorrelation because they arise from latent physical processes. To generate trajectories with an appropriate degree of autocorrelation, the point predictor and neural RBM components are combined with a learnable degree of autocorrelation. At each time point (t_k), the sampled outcome is obtained from the neural RBM, with the mean parameter derived from an autoregressive combination,
mu(t_k, c, v_0) := p(v_0, c, t_k) - A(c, t_k - t_{k-1})*(v_{k-1} - p(v_0, c, t_{k-1})).
Here, A(c, t_k - t_{k-1}) is a learnable function controlling the decay rate of the autoregressive process, capturing the temporal continuity of disease progression.
Likewise, the precision parameter, denoted P(v_0, c, t_k-t_{k-1}), is the output of a neural network conditioned on the trial participant's baseline measurements and the time step.
Therefore sampling a trajectory proceeds by starting with a participant's baseline values, predicting the subsequent next step’s mean via an autoregressive law, and then sampling the neural RBM centered at the predicted mean with predicted precision. Then rinse and repeat.
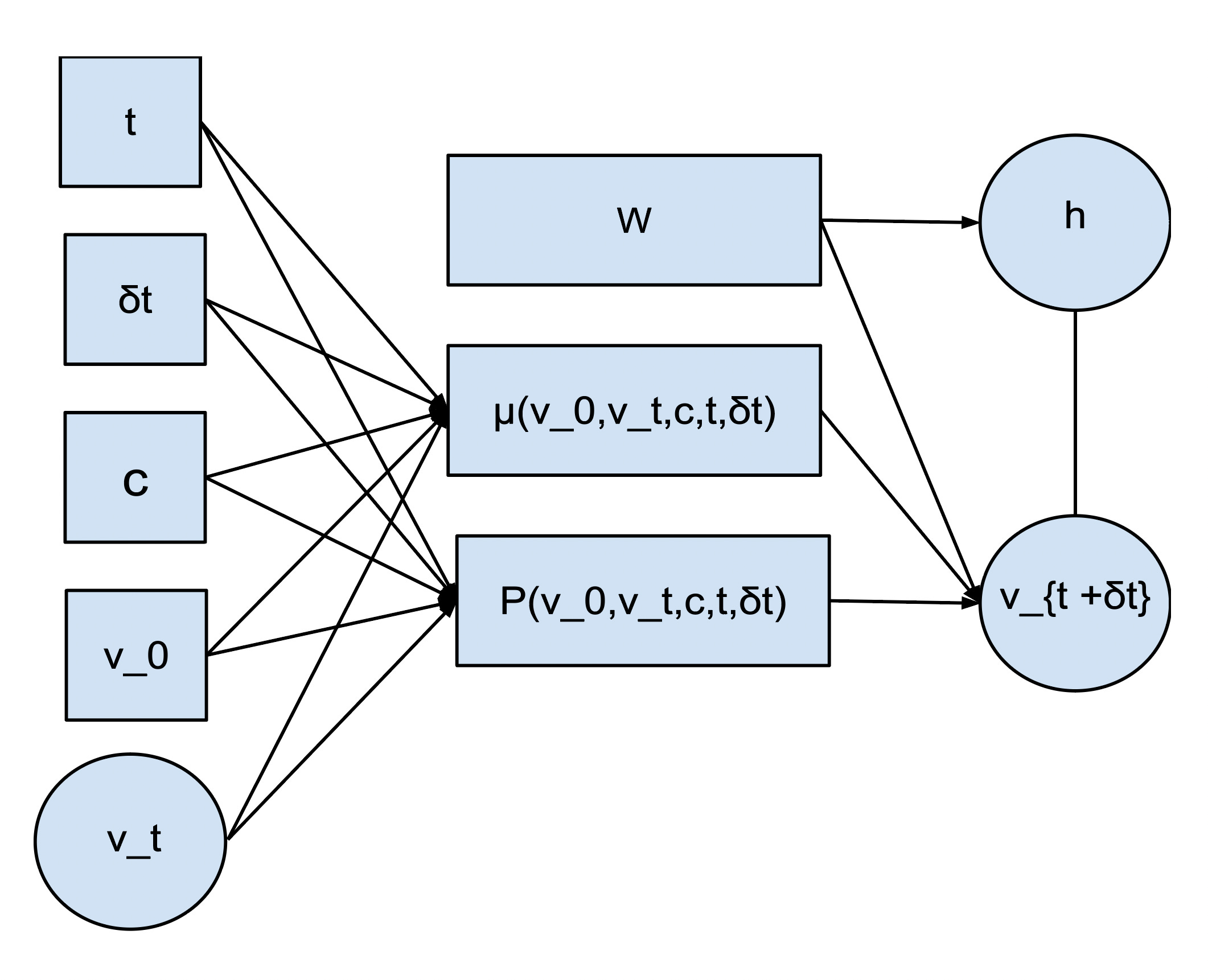
Factor graph of neural RBM for autoregressive time-series generation
One issue that hasn’t been addressed so far is how we cope with the ever-present problem of missing data. Our model architecture includes an innovative approach to handling missing data by incorporating a "missing attention" layer. Here the model combines imputation of missing values with attention-based adjustment of features according to the patterns of missingness in the data. This scheme, therefore, provides a means to both impute missing values and pass a missingness-aware signal to subsequent layers.
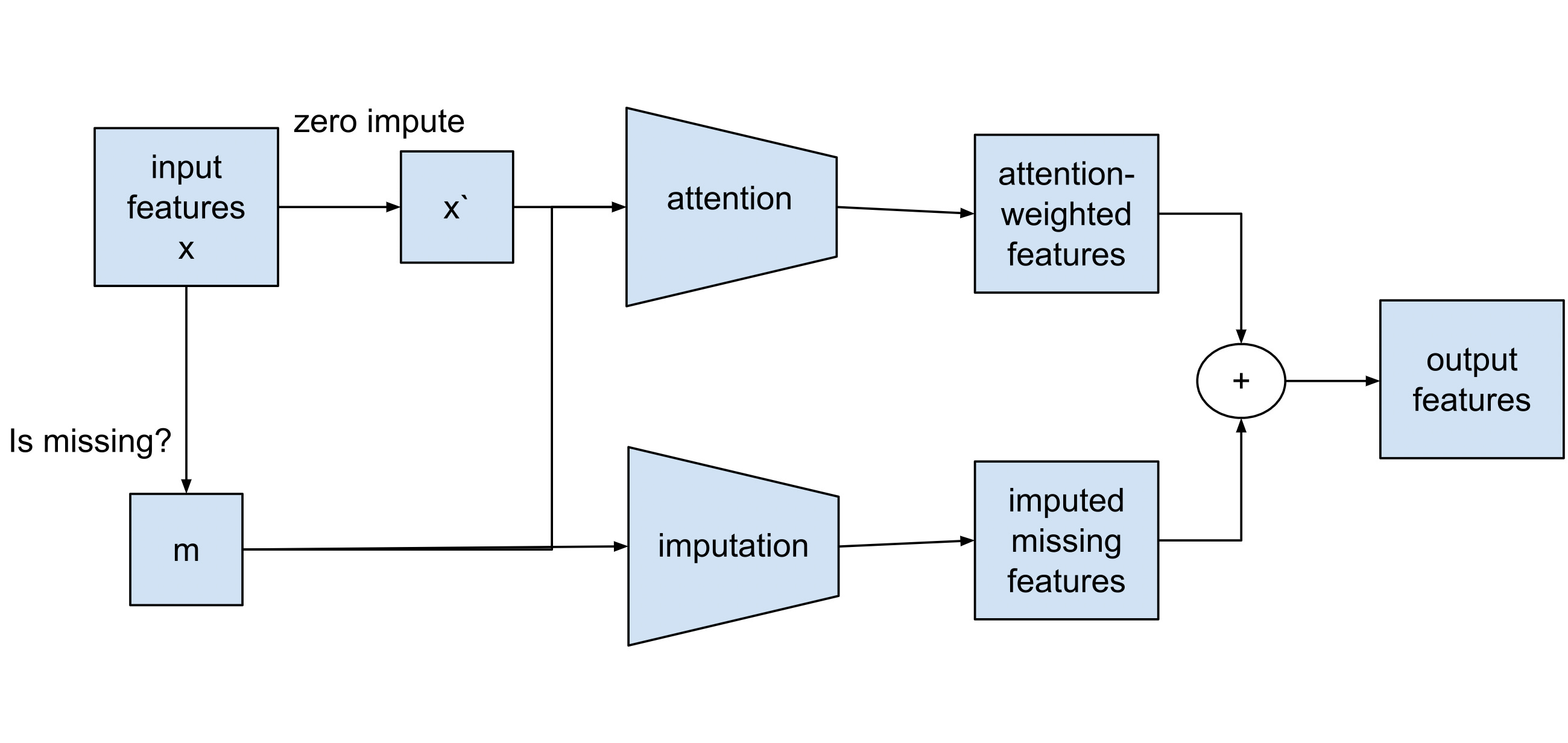
Neural diagram of the missing attention mechanism
The entire model architecture, with its differentiable components, can be trained end-to-end through a contrastive divergence-based approximation of the neural RBM likelihood. This allows the model training process to optimize each of the components of the model simultaneously in concert—the most desirable training scenario to have.
Looking ahead, we aim to employ versions of this architecture to generate a large and robust set of DTGs across various disease areas in the near future. The potential for personalized disease forecasting and the acceleration of clinical trials represents a significant leap forward in the quest for improved patient outcomes.
Stay tuned as we continue to revolutionize disease forecasting, empowering healthcare professionals and researchers with powerful tools to advance medical knowledge and enhance patient care. For more information about Unlearn.ai and our DTG models, please visit our website and follow our latest updates.






