


March 1, 2023
Clinical trials are typically used to assess how well a new treatment performs within a population, on average. However, it’s likely that a given treatment will have different effects on different people. Sometimes researchers will examine groups of similar patients (e.g., males and females) but, in reality, each patient is unique. That’s why we’ve been working on a new approach to understanding these “heterogeneous treatment effects” at the most detailed level—the individual patient.
Before we get into that though, I guess we need to talk about p-values …
The poor p-value is a much maligned statistic. I’ve written before on how I don’t like the way p-values are typically used (i.e., compared to an arbitrary threshold), but that’s not particularly relevant here. In any case, to compute one, we need a hypothesis expressed as a probability distribution and an observation. In simple terms, the p-value is the probability of seeing something equal to, or greater than, the observation, assuming the hypothesis is true. More technically, the p-value is an area of the tail of the hypothetical probability distribution. It is a measure of how compatible the observation is with the hypothesis.
Anyone who’s ever read a NEJM paper knows that p-values are commonly used to compare two treatments in clinical trials. The scientific hypothesis is that there is no difference between the two treatments, on average. Randomly assigning the participants in the trial to receive one treatment or the other allows one to express this scientific hypothesis as a probability distribution. Given an observed difference in outcomes between the treatment and control group, we can compute the probability of seeing an equal or larger difference assuming that the effects of the two treatments are the same, on average, by considering the probability distribution created by looking at all of the ways we could have randomly assigned the participants into two equal groups. The resulting p-value is a measure of compatibility—”is the observed difference between the two groups compatible with the hypothesis that the two treatments were the same, on average?”.
Alright, I’m sure you’re familiar with the usual p-values and are already bored of hearing about it by now. Maybe you’re tired of reading the phrase “on average”. So, let’s talk about how we can compute a p-value for an individual patient in a clinical trial to assess if he/she had an unexpected response.
First, we need a probability distribution describing the potential outcomes for a patient if he/she were to receive the standard of care. That’s not easy to get, but new machine learning techniques make it possible. We can estimate this probability distribution using a generative model trained on historical data from a large population of patients. Just like you can prompt a language model and let it generate text, we can condition the generative model on observed data from a patient of interest and let it generate his/her potential futures. For the sake of clarity, let’s focus on a single outcome (Δxi) like a change from baseline of a disease activity index so that our generative model describes the distribution Pr[Δxi].
Note that this has to be a generative model, a regular ol’ discriminative model won’t cut it because it will mess up the distribution, but that’s a topic for another time.
Now that we have a distribution describing our hypothesis, we need an observation. So, we wait until the end of the clinical trial and observe how the patient responded to the treatment he/she received. The last thing we have to do is to use our generative model to compute the probability of seeing something greater than, or equal to, the observed value (e.g., pi = Pr[Δxi > obs]). That’s it! Now we have a personal p-value.
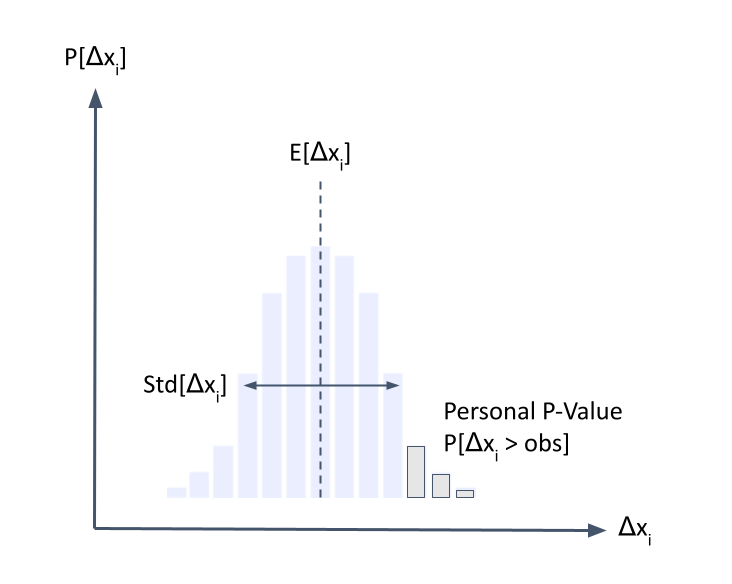
So what does a personal p-value do? It tells us how compatible a patient’s observed outcome is with the hypothesis that he/she received the standard of care. That is, how unexpected would it be for the patient to respond this way to the standard treatment?
If a patient on a new treatment had a low personal p-value, then it’s unlikely he/she would have responded that well to the standard treatment; instead, it’s likely he/she benefited from the new treatment. On the other hand, if a patient on a new treatment had a high personal p-value, then his/her response on the new treatment isn’t any better than would be expected with the standard treatment. It’s like a subgroup analysis, but with only one patient per group!
I think these personal p-values are a pretty cool idea, and although there’s still some technical challenges to overcome in how to compute and use them, they’ll open up a whole new way to view clinical trial results. Why settle for averages when you can look at individuals?





